安装
Linux用户建议从Nodesource安装,支持Debian和RHEL系,添加软件源后可通过包管理组件安装与更新,废话不多说,直接上命令,以Debian 12为例:
不要安装系统软件仓库里的,版本过旧(可自行通过
apt-cache policy nodejs查看,Debian 12还在v18)
1 | |
1 | |
1 | |
主题
Hexo自带了一个默认主题Landscape。你也可以随意安装使用其他主题。如果你对此一无所知,推荐你去看看这位大佬的文章:16 款精美的 hexo 博客主题推荐,对16个主题做了详细的描述,并配有效果图,你可以从中挑选一款自己喜欢的
我最终选择了Fluid主题,接下来也将以这个主题为例讲述如何配置
1 | |
现在目录中应该有三个配置文件:Hexo配置文件_config.yml,默认主题Landscape配置文件_config.landscape.yml,以及刚刚下载的主题配置文件_config.fluid.yml,你只需要关心Hexo配置文件以及你选择的主题的配置文件即可。接下来只会讲述功能上的配置,与美化等自定义有关的配置请自行参考Hexo与主题文档
写作与内容管理
对于博客来说,最重要的就是其中的内容了。在Hexo中,兴建一篇文章的指令很简单:
1 | |
你可以使用Markdown格式来撰写文章,如果你不会Markdown,推荐你去看看这篇教程:Markdown 教程。比起各类office套件,使用Markdown撰写文章可以让你专注于内容而非排版。
文章撰写完成后,你可以执行hexo serve指令,Hexo会自动将你写的内容转换为html静态文件,此时在浏览器中打开localhost:4000便可以直接预览生成的网页。
接下来做一些(我认为的)可以让你的写作与管理变得更加方便的调整
将图片放入子文件夹
在Hexo中,图片必须放置在source目录中或其子文件夹中。同时,图片的根路径即为source文件夹(即文章中img.jpg等同于文件系统中的/path/to/hexo/source/img.jpg)。你可以将所有图片放置在一个文件夹中,但这样不便于管理。我们可以让Hexo在创建新文章的时候,同步创建一个同名文件夹用来存放素材,类似于这样:
你需要向_config.yml中加入以下配置:
1 | |
但是,在向文章中添加图片的时候,以Markdown插入图片的方式直接填写图片的文件名是无法正确显示图片的(在Hexo眼中,图片的路径是/_posts/<title>/img.png)。正确的做法是使用相对路径引用的标签插件,类似于这样:
1 | |
但这并不符合Markdown语法规范,同时也十分麻烦。对此我们可以安装hexo-renderer-marked插件,并通过配置使得使用Markdown格式插入的图片可以被解析到正确的地址。
首先安装插件
1 | |
然后在_config.yml中加入以下配置:
1 | |
更多功能请参考其官方文档
安装vscode插件
图片在网页上是能正常显示了,但我们在使用Markdown格式插入图片时只写了图片的文件名,而图片的真实地址其实是<title>/img.png,这导致了一个问题:当我们在本地编辑的时候,我们又无法预览插入的图片了,这可怎么办?
我使用的Markdown编辑器是vscode,这款插件解决了这个痛点,我们只需要安装即可
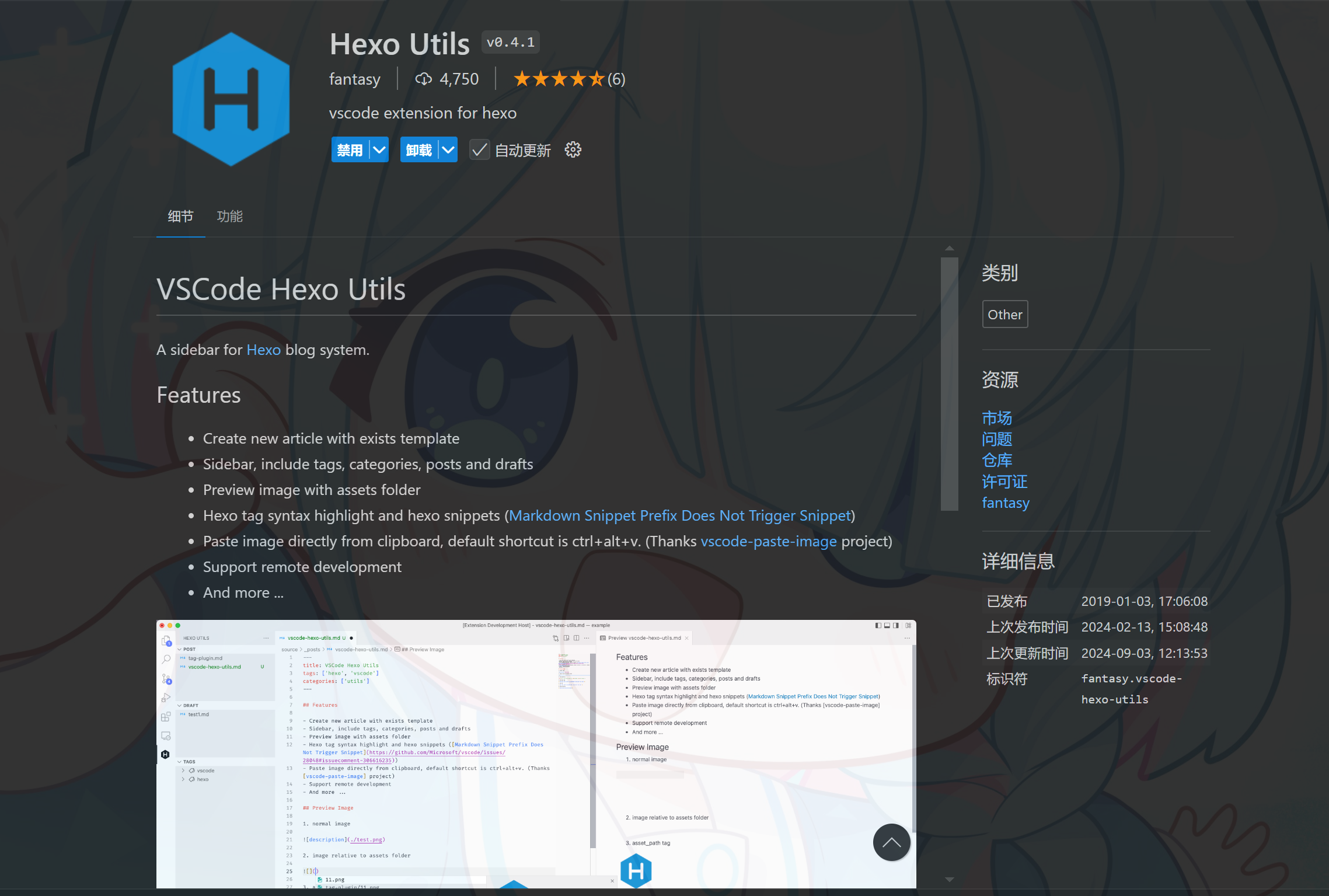
安装完成后就可以直接在预览区域查看图片了
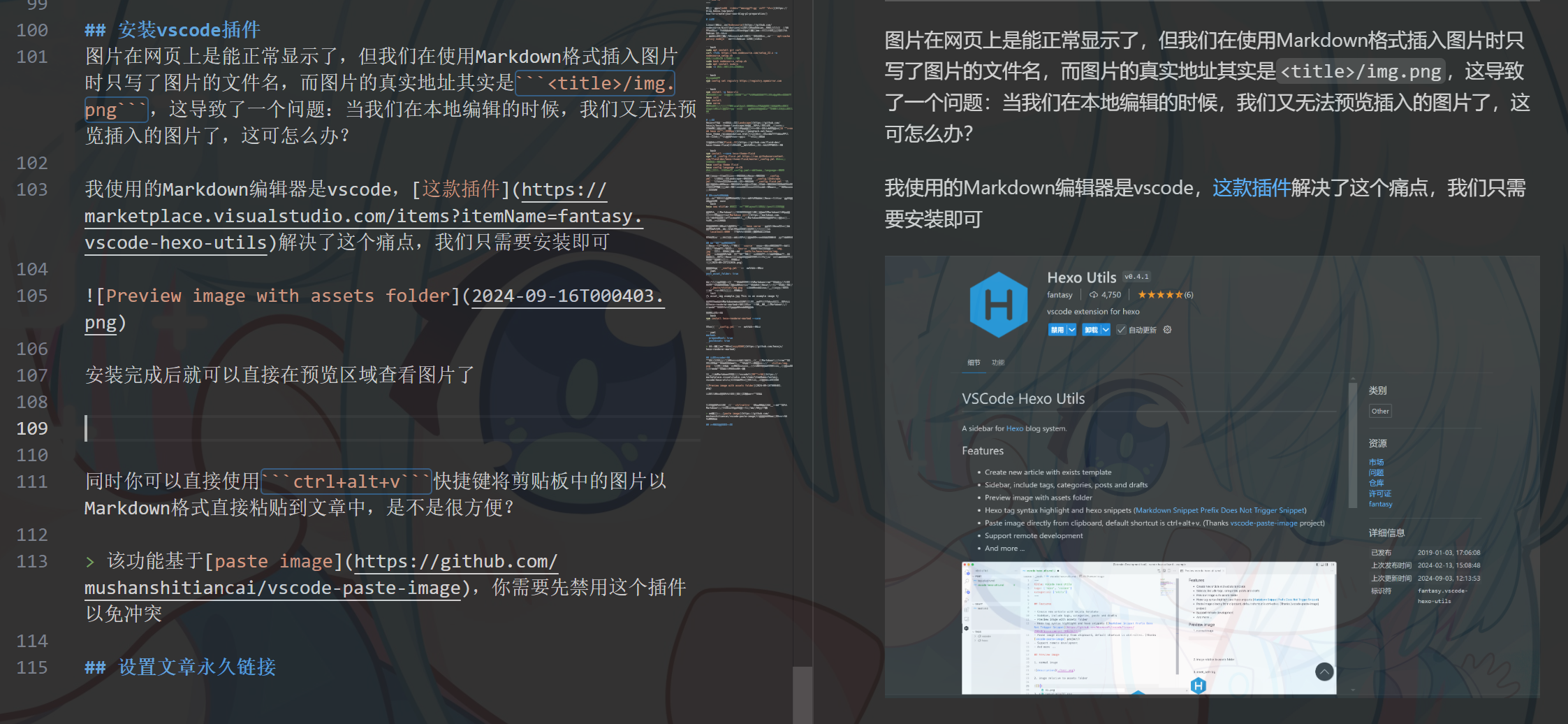
同时你可以直接使用ctrl+alt+v快捷键将剪贴板中的图片以Markdown格式直接粘贴到文章中,是不是很方便?
该功能基于paste image,你需要先禁用这个插件以免冲突
自定义模板
Hexo的模板存放在scaffolds文件夹下,创建新文章时会将post.md文件复制一份到source文件夹。通过编辑这个文件,你可以自定义每篇文章的Front-matter以及一些固定的正文内容。我将其配置成这样:
1 | |
设置文章永久链接
文章永久链接,即_config.yml中的permalink参数,控制了博客文章的链接形式,默认是年-月-日-标题的形式。但这样设置的链接过长,同时美观性欠佳。我决定将所有文章放在/post路径下,并且为每篇文章取一个简短的英文标题作为链接的一部分。
首先修改permalink参数:
1 | |
再向每篇文章的Front-matter部分插入title_en参数即可,上个部分设置的模板中已包含。
RSS
RSS(英文全称:RDF Site Summary 或 Really Simple Syndication),是一种消息来源格式规范,用以聚合多个网站更新的内容并自动通知网站订阅者。使用 RSS 后,网站订阅者便无需再手动查看网站是否有新的内容,同时 RSS 可将多个网站更新的内容进行整合,以摘要的形式呈现,有助于订阅者快速获取重要信息,并选择性地点阅查看。(引自维基百科页面)
1 | |
安装完成后,生成静态文件时将会自动生成RSS文件,默认放置在/atom.xml路径。我将RSS标识放在了博客的导航菜单上,需要在_config.fluid.yml文件中增加一行配置:
1 | |
之所以没有修改
_config.yml文件是因为我觉得默认配置足矣,如果你需要更多的自定义选项,请参考插件文档
访问统计
即文章标题下方的阅读量以及页脚的访问量与访问数,这里我们使用Leancloud统计数据
Leancloud分国内版和国际版,国际版的API地址屏蔽了国内IP,因此为了保证数据准确,请使用国内版(虽然国际版不需要实名认证就能用)
首先打开官网,注册账号并实名认证,无需多言。
完成之后,返回主页,点击创建应用,应用名称随意,计价方案选开发版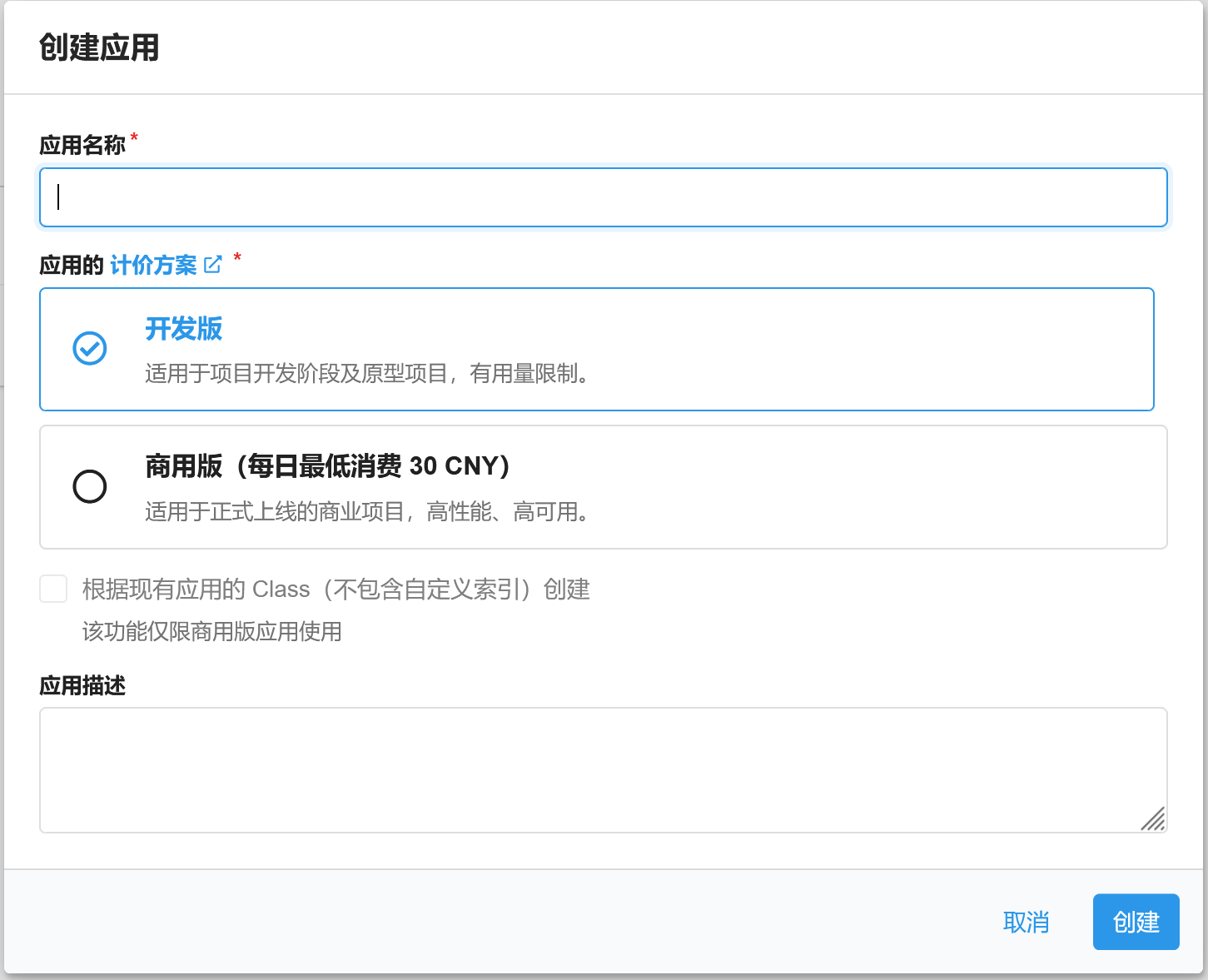
然后点击创建好的应用下方的设置,再点击左侧边栏的应用凭证,记下AppID,AppKey和REST API 服务器地址三个参数,将其填入_config.fluid.yml文件中web_analytics下的leancloud部分中,再修改statistics和views中source参数为leancloud即可
推送到Github
最后一步,我们需要将生成的静态文件推送到Github仓库中,以便Netlify拉取并构建网页。
首先安装git部署插件
1 | |
然后在Github上创建一个新的仓库用于存放博客的静态文件,由于我们不使用Github Pages服务,因此仓库的名称随意。
然后我们需要配置ssh密钥用于向我们刚刚创建的仓库提交文件,参考方法如下:
首先使用ssh-keygen生成一个密钥对
默认生成RSA密钥,需要ECC密钥可手动指定 -t ed25519,所有问题回车确认即可(可能需要提供一个密钥文件名以免与现有的密钥冲突)
然后前往Github的SSH Keys页面,点击New SSH Key,将你的公钥文件(类似rsa.pub)粘贴进去
然后,在~/.ssh目录下新建一个config文件,内容填入主机名,用户以及密钥文件路径,类似于这样:
1 | |
完成之后可以使用ssh -T git@github.com指令测试连接,应该会得到以下回复:
1 | |
然后在_config.yml文件末尾加入以下配置:
1 | |
最后,使用hexo deploy指令即可生成静态文件并推送到Github仓库内
总结
至此,在本地进行的工作全部完成,在下一篇文章中,我们将会使用Netlify进行博客页面的部署,同时为博客添加评论区以及反垃圾系统,并将我们的博客添加到搜索引擎上,敬请期待~
]]>